笔记
代码块
静态代码块
在类被加载的时候就运行了,而且只运行一次,并且优先于各种代码块以及构造函数。如果一个类中有多个静态代码块,会按照书写顺序依次执行。静态代码块不能存在任何方法体中静态代码块不能访问普通变量
构造代码块
在创建对象时被调用,每次创建对象都会调用一次,但是优先于构造函数执行。需要注意的是,构造代码块不是优先于构造函数执行,而是依托于构造函数,也就是说,如果你不实例化对象,构造代码块是不会执行的
普通代码块
和构造代码块的区别是,构造代码块是在类中定义的,而普通代码块是在方法体中定义的。且普通代码块的执行顺序和书写顺序一致
静态代码块>构造代码块(类中定义)>构造函数>普通代码块(方法中定义)
内部类
成员内部类
也是最普通的内部类,它是外围类的一个成员,所以他是可以无限制的访问外围类的所有成员属性和方法,尽管是private的,但是外围类要访问内部类的成员属性和方法则需要通过内部类实例来访问。
在成员内部类中要注意两点,第一:成员内部类中不能存在任何static的变量和方法;第二:成员内部类是依附于外围类的,所以只有先创建了外围类才能够创建内部类。
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.getOuterClass().display();局部内部类
有这样一种内部类,它是嵌套在方法和作用域内的,对于这个类的使用主要是应用与解决比较复杂的问题,想创建一个类来辅助我们的解决方案,到那时又不希望这个类是公共可用的,所以就产生了局部内部类,局部内部类和成员内部类一样被编译,只是它的作用域发生了改变,它只能在该方法和属性中被使用,出了该方法和属性就会失效。
静态内部类
使用static修饰的内部类我们称之为静态内部类,不过我们更喜欢称之为嵌套内部类。静态内部类与非静态内部类之间存在一个最大的区别,我们知道非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围内,但是静态内部类却没有。没有这个引用就意味着:
- 它的创建是不需要依赖于外围类的。
- 它不能使用任何外围类的非static成员变量和方法。
- 在静态内部类中可以存在静态成员
- 静态内部类只能访问外围类的静态成员变量和方法,不能访问外围类的非静态成员变量和方法
- 非静态内部类中不能存在静态成员,非静态内部类中可以调用外围类的任何成员,不管是静态的还是非静态的
- 静态内部类可以直接创建实例不需要依赖于外围类
- 非静态内部的创建需要依赖于外围类方位
- 非静态内部类的成员需要使用非静态内部类的实例new
匿名内部类
new父类构造器(参数列表)|实现接口(){
//匿名内部类的类体部分
}
在这里我们看到使用匿名内部类我们必须要继承一个父类或者实现一个接口,当然也仅能只继承一个父类或者实现一个接口。同时它也是没有class关键字,这是因为匿名内部类是直接使用new来生成一个对象的引用。当然这个引用是隐式的。
- 使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。
- 匿名内部类中是不能定义构造函数的。
- 匿名内部类中不能存在任何的静态成员变量和静态方法。
- 匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
- 匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(title);
}
});使用内部类的优势
封装性、实现多继承※、用匿名内部类实现回调功能、解决继承及实现接口出现同名方法的问题
| 详解内部类 | 深入理解Java:内部类 | Java内部类有坑,100%内存泄露! |
|---|
元注解
@Retention
表示需要在什么级别保存该注释信息,用于描述注解的生命周期(即:被描述的注解在什么范围内有效),取值(RetentionPoicy)有:
- SOURCE:在源文件中有效(即源文件保留)
- CLASS:在class文件中有效(即class保留)
- RUNTIME:在运行时有效(即运行时保留)
@Target
用于描述注解的使用范围(即:被描述的注解可以用在什么地方),取值(ElementType)有:
- CONSTRUCTOR:用于描述构造器
- FIELD:用于描述域
- LOCAL_VARIABLE:用于描述局部变量
- METHOD:用于描述方法
- PACKAGE:用于描述包
- PARAMETER:用于描述参数
- TYPE:用于描述类、接口(包括注解类型)或enum声明
- ANNOTATION_TYPE:标明注解可以用于注解声明(应用于另一个注解上)
- TYPE_PARAMETER:表示该注解能写在类型参数的声明语句中也就是泛型上,类型参数声明如下:<T>,< T extends Person>
- TYPE_USE:表示注解可以在任何用到该类的地方使用
@Inherited
标记这个注解是继承于哪个注解类(默认注解并没有继承于任何子类)
@Documented
标记这些注解是否包含在用户文档中。
@Repeatable
重复注解,在java8中新增了一个方法getAnnotationsByType,用于获取可重复的注解,返回类型是数组
| 你知道Java中的注解是如何工作的? | 深入理解Java:注解 | JDK中注解的底层原来是这样实现的 |
|---|---|---|
| 原来注解是这么实现的啊 |
构建工具
Maven
常用命令
mvn package、install、deploy区别
package:完成了项目编译、单元测试、打包功能,但没有把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库
install:完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库,但没有布署到远程maven私服仓库
deploy:完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库compile(编译 打包)
compile是默认的范围;如果没有提供一个范围,那该依赖的范围就是编译范围。编译范围依赖在所有的classpath中可用,同时它们也会被打包。provided(已提供 编译不打包)
provided意味着打包的时候可以不用包进去,别的设施(Web Container)会提供。事实上该依赖理论上可以参与编译,测试,运行等周期。相当于compile,但是在打包阶段做了exclude的动作。runtime(运行时 不编译打包)
runtime表示被依赖项目无需参与项目的编译,不过后期的测试和运行周期需要其参与。与compile相比,跳过编译而已。test (测试)
test范围依赖在一般的编译和运行时都不需要,它们只有在测试编译和测试运行阶段可用。system (系统)
Maven不会在仓库中去寻找它。如果你将一个依赖范围设置成系统范围,你必须同时提供一个systemPath元素。注意该范围是不推荐使用的(建议尽量去从公共或定制的Maven仓库中引用依赖)<dependency> <groupId>com.example</groupId> <artifactId>local-jar-name</artifactId> <version>1.0.0</version> <scope>system</scope> <systemPath>${project.basedir}/lib/local-jar-name.jar</systemPath> <!-- ${pom.basedir}:表示pom文件的目录 --> </dependency> <!-- springboot打jar包时将本地jar也添加进去 --> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <includeSystemScope>true</includeSystemScope> </configuration> </plugin>import(导入)
import仅支持在<dependencyManagement>中的类型依赖项上。它表示要在指定的POM<dependencyManagement>部分中用有效的依赖关系列表替换的依赖关系。该scope类型的依赖项实际上不会参与限制依赖项的可传递性。<optional>标签
projectA依赖projectB,projectB依赖projectC时,当projectA在maven引入projectB时,如果projectB写上<optional>true</optional>时,则projectA不依赖projectC,即projectA可以自己选择是否依赖projectC,如果不写或者是false的时候,则projectA引入projectB时,也会引入projectC,默认<optional>的值为false,即子项目必须依赖.但是像引入parent继承情况时,像这样<dependencyManagement> <dependencies> <dependency> <groupId>joda-time</groupId> <artifactId>joda-time</artifactId> <version>2.9.9</version> <optional>true</optional> </dependency> </dependencies> </dependencyManagement>optional选项在统一控制版本的情况下会失效
Maven打包跳过测试的5种方法
(1) 命令行方式
# -DskipTests=true,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下。
mvn package -DskipTests=true
# -Dmaven.test.skip=true,不执行测试用例,也不编译测试用例类。
mvn package -Dmaven.test.skip=true(2) pom.xml
<build>
<plugins>
<!-- maven打包时跳过测试 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>(3) IDEA图标Skip Tests。点击选中,再用LifeCycle中的打包就会跳过测试
(4) 打开配置,找到Build,Exxcution,Deployment–>Build Tools–>Maven–>Runner,在VM option中添加-Dmaven.test.skip=true或者-DskipTests=true,就能在打包时跳过测试。
(5) 打开配置,找到Build,Exxcution,Deployment–>Build Tools–>Maven–>Runner,在Properties中勾选Skip Test选项。
Gradle
implementation,默认的scope,取代compile(已弃用)。implementation的作用域会让依赖在编译和运行时均包含在内,但是不会暴露在类库使用者的编译时。举例,如果我们的类库包含了gson,那么其他人使用我们的类库时,编译时不会出现gson的依赖。
api,和implementation类似,都是编译和运行时都可见的依赖。但是api允许我们将自己类库的依赖暴露给我们类库的使用者。
compileOnly和runtimeOnly,这两种顾名思义,一种只在编译时可见,一种只在运行时可见。而runtimeOnly和Maven的provided比较接近。runtimeOnly取代了runtime(不建议使用)
testImplementation,这种依赖在测试编译时和运行时可见,类似于Maven的test作用域。
testCompileOnly和testRuntimeOnly,这两种类似于compileOnly和runtimeOnly,但是作用于测试编译时和运行时。
compileClasspath延伸compile,compileOnly,implementation。编译类路径,在编译源代码时使用。由任务使用compileJava。runtimeClasspath延伸runtimeOnly,runtime,implementation,运行时类路径包含实现的元素以及仅运行时元素。
annotationProcessor编译期间使用的注释处理器。
String相关
String.intern()是一个Native方法,底层调用C++的StringTable::intern方法实现。当通过语句str.intern()调用intern()方法后,JVM就会在当前类的常量池中查找是否存在与str等值的String,若存在则直接返回常量池中相应Strnig的引用;若不存在,则会在常量池中创建一个等值的String,然后返回这个String在常量池中的引用,通俗的讲,是将字符串放入常量池中。是一种手动将字符串加入常量池中的方法
String.toUpperCase()会在内存中新建一个字符串并不会修改原来的字符串
String对象new出来的字符串是放在堆中,直接赋值的字符串是放在常量池中的。
对字符串做拼接操作,即做“+”运算,分两种情况:
①表达式右边是纯字符串常量,则存放在常量池中
②表达式右边存在字符串引用,则存放在堆中String a = "s"; String b = "b"; String c = a+b;//变量形式相加底层new String()不放常量池 String d = "s"+"b";//非变量形式相加放到常量池 String e = "sb";//放到常量池 String f = new String("sb");//不放常量池 String g = f.intern();//手动放到常量池 System.out.println(d==e);//true System.out.println(c==e);//false System.out.println(c==f);//false System.out.println(c==d);//false System.out.println(e==f);//false System.out.println(e==g);//true String s1 = new String("计算机"); String s2 = s1.intern(); String s3 = "计算机"; System.out.println(s2);//计算机 System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象一个是常量池中的String对象, System.out.println(s3 == s2);//true,因为两个都是常量池中的String对 String str1 = "str"; String str2 = "ing"; String str3 = "str" + "ing";//常量池中的对象 String str4 = str1 + str2; //在堆上创建的新的对象 String str5 = "string";//常量池中的对象 System.out.println(str3 == str4);//false System.out.println(str3 == str5);//true System.out.println(str4 == str5);//false String a = "a"; String b = a; System.out.pringln(a == b);trueString字符串有长度限制,在编译期,要求字符串常量池中的常量不能超过65535,并且在javac执行过程中控制了最大值为65534。
在运行期,长度不能超过Int的范围,否则会抛异常。common-lang3包StringUtils
isEmpty// 如果是null或者“”则返回true。 isBlank// 如果是null或者“”或者空格或者制表符则返回true。isBlank判空更加准确。
try、catch、finally
- try中的return语句先执行了但并没有立即返回,等到finally执行结束后再return
- finally块中的return语句会覆盖try块中的return返回
- 如果finally语句中没有return语句覆盖返回值,那么原来的返回值可能因为finally里的修改而改变也可能不变
- try块里的return语句在异常的情况下不会被执行,这样具体返回哪个看情况
- 当发生异常后,catch中的return执行情况与未发生异常时try中return的执行情况完全一样
- finally块的语句在try或catch中的return语句执行之后返回之前执行且finally里的修改语句可能影响也可能不影响try或catch中return已经确定的返回值,若finally里也有return语句则覆盖try或catch中的return语句直接返回。
几个经典问题
equals和hashcode的关系
- 如果两个对象相同(即用equals比较返回true),那么它们的hashCode值一定要相同;
- 如果两个对象的hashCode相同,它们并不一定相同(即用equals比较返回false)
重写equals为什么需要重写hashcode
比较对象先比较hashcode,hashcode相同在比较equals。如果equals为true而hashcode不同的话就会造成hashmap的key可能会重复,因为jdk判断hashmap的key是否为重复首先判断hashcode是否一致,不一致的话直接判定不是同一个对象,而equals则判定对象为一个对象违背了hashmap的设计原则,重写hashCode方法,是为了在一些算法中避免我们不想要的冲突和碰撞
Java为什么不支持多重继承
有两个类B和C继承自A;假设B和C都继承了A的方法并且进行了覆盖,编写了自己的实现;假设D通过多重继承继承了B和C,那么D应该继承B和C的重载方法,那么它应该继承的是B的还是C的?这就陷入了矛盾,所以Java不允许多重继承。
Java8中的接口和抽象类到底还有啥区别?
既然接口都能写默认方法了,那么还要抽象类干嘛呢?
区别1:首先抽象类是一个“类”,而接口只是一个“接口”,两者的概念和应用场景不一样,这也是抽象类和接口的主要区别。
区别2:即使在Java8中接口也能写实现方法了,但却不能写构造方法,而在抽象类是可以写构造方法的,意味着抽象类是参与类的实例化过程的,而接口则不是。抽象类不可以new
区别3:抽象类可以有自己的各种成员变量,并且可以通过自己的非抽象方法进行改变,而接口中的变量默认全是public static final修饰的,意味着都是常量,并且不能被自己和外部修改。
区别4:接口可以实现多继承,而抽象类只能单继承
Comparable和Comparator区别
- 一个类实现了Comparable接口,意味着该类的对象可以直接进行比较(排序),但比较(排序)的方式只有一种,很单一。一个类如果想要保持原样,又需要进行不同方式的比较(排序),就可以定制比较器(实现Comparator接口)。
- Comparable接口在java.lang包下,而Comparator接口在java.util包下。
- 如果对象的排序需要基于自然顺序,请选择Comparable,如果需要按照对象的不同属性进行排序,请选择Comparator
过滤器和拦截器的区别
- Filter需要在web.xml中配置,依赖于Servlet;Interceptor需要在SpringMVC中配置,依赖于框架;
- Filter的执行顺序在Interceptor之前
- 两者的本质区别:拦截器(Interceptor)是基于Java的反射机制,而过滤器(Filter)是基于函数回调。从灵活性上说拦截器功能更强大些,Filter能做的事情,都能做,而且可以在请求前,请求后执行,比较灵活。Filter主要是针对URL地址做一个编码的事情、过滤掉没用的参数、安全校验(比较泛的,比如登录不登录之类),太细的话,还是建议用interceptor。不过还是根据不同情况选择合适的。
- 拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
- 在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次。init(),destroy()各一次,dofilter()多次
- 拦截的请求范围不同,过滤器几乎可以对所有进入容器的请求起作用,而拦截器只会对Controller中请求或访问static目录下的资源请求起作用。
- 触发时机不同,过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。拦截器Interceptor是在请求进入servlet后,在进入Controller之前进行预处理的,Controller中渲染了对应的视图之后请求结束。
| 过滤器、监听器、拦截器的区别 | 一口气说出过滤器和拦截器6个区别 | SpringBoot过滤器、拦截器、监听器对比及使用场景 |
|---|
泛型
List<? extends Object >相当于List<?>
在Java集合框架中,对于参数值是未知类型的容器类,只能读取其中元素,不能向其中添加元素,因为,其类型是未知,所以编译器无法识别添加元素的类型和容器的类型是否兼容,唯一的例外是NULLList<? extends T>可以添加元素添加的元素为T或T的子类List<? super T>可以添加元素添加的元素为T或T的父类
web.xml详解
<context-param> 元素含有一对参数名和参数值,用作应用的Servlet上下文初始化参数,参数名在整个Web应用中必须是惟一的,在web应用的整个生命周期中上下文初始化参数都存在,任意的Servlet和jsp都可以随时随地访问它。在JSP网页中可以使用下列方法来取得:
${initParam.param_name}若在Servlet可以使用下列方法来获得:
String param_name=getServletContext().getInitParamter("param_name");Servlet的ServletConfig对象拥有该Servlet的ServletContext的一个引用,所以可这样取得上下文初始化参数:
getServletConfig().getServletContext().getInitParameter()也可以在Servlet中直接调用
getServletContext().getInitParameter(),两者是等价的。
<listener> 为web应用程序定义监听器,监听器用来监听各种事件,比如:application和session事件,所有的监听器按照相同的方式定义,功能取决去它们各自实现的接口,常用的Web事件接口有如下几个:
- ServletContextListener:用于监听Web应用的启动和关闭;
- ServletContextAttributeListener:用于监听ServletContext范围(application)内属性的改变;
- ServletRequestListener:用于监听用户的请求;
- ServletRequestAttributeListener:用于监听ServletRequest范围(request)内属性的改变;
- HttpSessionListener:用于监听用户session的开始和结束;
- HttpSessionAttributeListener:用于监听HttpSession范围(session)内属性的改变
<load-on-startup>1</load-on-startup/>
load-on-startup元素标记容器是否应该在web应用程序启动的时候就加载这个servlet,(实例化并调用其init()方法)。它的值必须是一个整数,表示servlet被加载的先后顺序。如果该元素的值为负数或者没有设置,则容器会当Servlet被请求时再加载。如果值为正整数或者0时,表示容器在应用启动时就加载并初始化这个servlet,值越小,servlet的优先级越高,就越先被加载。值相同时,容器就会自己选择顺序来加载创建Servlet实例有两个时机较小的优先加载
进制转换
十进制转换二进制
一直除以2最后的商+余数开始排序
5/2=2余1,2/2 =1余0,所以5的二进制为101
6/2=3余0,3/2=1余1,所以6的2进制是110
二进制转换十进制
1 0 1
1* 2的2次方 + 0 * 2的1次方 + 1 * 2 的0次方 = 5
运算符
“<<”左移运算符
转换为二进制后左移 例:2<<3 即2的二进制左移三位
2的二进制为2/2=1余0 , 10左移三位后补0 (00000010)(00010000)
n<<3 可以转换为 n * 2 ^ 3
“>>”右移运算符
转换为二进制后右移 例:8>>3 即8的二进制右移三位
8的二进制为8/2=4余0 ,4/2=2余0, 2/2=1余0, 1000右移三位(删除后三位) (0000001000)(000000001)为1
n>>3 可以转换为 n/2^3
& 运算符
如果相对应位都是1,则结果为1,否则为0
| 运算符
如果相对应位都是0,则结果为0,否则为1
** ^ 运算符**
如果相对应位值相同,则结果为0,否则为1
比较
^: 可以不借助第三块空间的方式交换两个变量的值
&: 在某些情况下可以取代%的运算
某些情况:当我们拿着一个正数去%上2的n次方数的时候,其实结果等价于我们拿着这个正数&上2的n次方数-1的结果
x % 2(n) == x & 2(n)-1
17 % 4 == 17 & 3
99 % 64 == 99 & 63
数据库相关知识点
SQL查询慢的原因
- sql没加索引
- sql索引不生效:
- 隐式的类型转换,索引失效,
- 查询条件包含or,可能导致索引失效,
- like通配符可能导致索引失效,
- 查询条件不满足联合索引的最左匹配原则,
- 在索引列上使用mysql的内置函数,
- 对索引进行列运算(如,+、-、*、/),索引不生效,
- 索引字段上使用(!=或者<>),索引可能失效,
- 索引字段上使用is null,is not null,索引可能失效,
- 左右连接,关联的字段编码格式不一样,
- 优化器选错了索引
- limit深分页问题
- 单表数据量太大
- join或者子查询过多
- in元素过多
- 数据库在刷脏页
- order by文件排序
- 拿不到锁
- delete + in子查询不走索引!
- group by使用临时表
- 系统硬件或网络资源
SQL优化
查询SQL尽量不要使用
select *,而是select具体字段。如果知道查询结果只有一条或者只要最大/最小一条记录,建议用limit 1
应尽量避免在where子句中使用or来连接条件
优化limit分页
优化你的like语句
使用where条件限定要查询的数据,避免返回多余的行
尽量避免在索引列上使用mysql的内置函数
应尽量避免在where子句中对字段进行表达式操作,这将导致系统放弃使用索引而进行全表扫
Inner join 、left join、right join,优先使用Inner join,如果是left join,左边表结果尽量小
应尽量避免在where子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
使用联合索引时,注意索引列的顺序,一般遵循最左匹配原则。
对查询进行优化,应考虑在where及order by涉及的列上建立索引,尽量避免全表扫描。
如果插入数据过多,考虑批量插入。
在适当的时候,使用覆盖索引。
慎用distinct关键字
删除冗余和重复索引
如果数据量较大,优化你的修改/删除语句。
where子句中考虑使用默认值代替null。
不要有超过5个以上的表连接
exist&in的合理利用
尽量用union all替换union
索引不宜太多,一般5个以内。
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型
索引不适合建在有大量重复数据的字段上,如性别这类型数据库字段。
尽量避免向客户端返回过多数据量。
当在SQL语句中连接多个表时,请使用表的别名,并把别名前缀于每一列上,这样语义更加清晰
尽可能使用varchar/nvarchar代替char/nchar。
为了提高group by语句的效率,可以在执行到该语句前,把不需要的记录过滤掉。
如果字段类型是字符串,where时一定用引号括起来,否则索引失效
使用explain分析你SQL的计划
水平拆分、垂直拆分
- 水平拆分,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
- 垂直拆分,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
| 分库分表的四个面时连环炮问题 | 这四种情况下,才是考虑分库分表的时候! | 分库分表?如何做到永不迁移数据和避免热点? |
|---|---|---|
| 这应该是最详尽的MySQL分库分表文章了 | 好好的系统,为什么要分库分表? |
主键、外键
- 主键(主码):主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
- 外键(外码):外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
为什么不推荐使用外键与级联?
对于外键和级联,阿里巴巴开发手册这样说到:
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明:以学生和成绩的关系为例,学生表中的student_id是主键,那么成绩表中的student_id则为外键。如果更新学生表中的student_id,同时触发成绩表中的student_id更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度
为什么不要用外键呢?大部分人可能会这样回答:
- 增加了复杂性:a.每次做DELETE或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便;b.外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
- 增加了额外工作:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
- 对分库分表不友好:因为分库分表下外键是无法生效的。
- ……
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
- 保证了数据库数据的一致性和完整性;
- 级联操作方便,减轻了程序代码量;
- ……
所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
关于数据库外键是否应该使用
外键提供的几种在更新和删除时的不同行为都可以帮助我们保证数据库中数据的一致性和引用合法性,但是外键的使用也需要数据库承担额外的开销,在大多数服务都可以水平扩容的今天,高并发场景中使用外键确实会影响服务的吞吐量上限。在数据库之外手动实现外键的功能是可能的,但是却会带来很多维护上的成本或者需要我们在数据一致性上做出一些妥协。我们可以从可用性、一致性几个方面分析使用外键、模拟外键以及不使用外键的差异:不使用外键牺牲了数据库中数据的一致性,但是却能够减少数据库的负载;模拟外键将一部分工作移到了数据库之外,我们可能需要放弃一部分一致性以获得更高的可用性,但是为了这部分可用性,我们会付出更多的研发与维护成本,也增加了与数据库之间的网络通信次数;使用外键保证了数据库中数据的一致性,也将全部的计算任务全部交给了数据库;在大多数不需要高并发或者对一致性有较强要求的系统中,我们可以直接使用数据库提供的外键帮助我们对数据进行校验,但是在对一致性要求不高的、复杂的场景或者大规模的团队中,不使用外键也确实可以为数据库减负,而大团队也有更多的时间和精力去设计其他的方案,例如:分布式的关系型数据库。当我们考虑应不应该在数据库中使用外键时,需要关注的核心我们的数据库承担这部分计算任务后会不会影响系统的可用性,在使用时也不应该一刀切的决定用或者不用外键,应该根据具体的场景做决策,我们在这里介绍了两个使用外键时可能遇到的问题:RESTRICT外键会在更新和删除关系表中的数据时对外键约束的合法性进行检查,保证外键不会引用到不存在的记录;CASCADE外键会在更新和删除关系表中的数据时触发对关联记录的更新和删除,在数据量较大的数据库中可能会有数量级的放大效果
数据库三大范式
数据库范式有3种:
- 1NF(第一范式):属性不可再分。
- 2NF(第二范式):1NF的基础之上,消除了非主属性对于码的部分函数依赖。
- 3NF(第三范式):3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。
1NF(第一范式)
属性(对应于表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再分为多个其他的字段了。1NF是所有关系型数据库的最基本要求,也就是说关系型数据库中创建的表一定满足第一范式。
2NF(第二范式)
2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。

一些重要的概念:
- 函数依赖(functionaldependency):若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作X→Y。
- 部分函数依赖(partialfunctionaldependency):如果X→Y,并且存在X的一个真子集X0,使得X0→Y,则称Y对X部分函数依赖。比如学生基本信息表R中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
- 完全函数依赖(Fullfunctionaldependency):在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
- 传递函数依赖:在关系模式R(U)中,设X,Y,Z是U的不同的属性子集,如果X确定Y、Y确定Z,且有X不包含Y,Y不确定X,(X∪Y)∩Z=空集合,则称Z传递函数依赖(transitivefunctionaldependency)于X。传递函数依赖会导致数据冗余和异常。传递函数依赖的Y和Z子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系R(学号,姓名,系名,系主任)中,学号→系名,系名→系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
3NF(第三范式)
3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。符合3NF要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系R(学号,姓名,系名,系主任)中,学号→系名,系名→系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合3NF的要求。
总结
- 1NF:数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,不能在一列中存放多个属性。例如员工信息表,不能在信息一列中放入电话,住址等信息,应该单独设计成电话、住址各一列
- 2NF:每个表必须有主键(Primary key),其他数据元素与主键一一对应。通常称这种关系为函数依赖(Functional dependence)关系,即表中其他数据元素都依赖于主键,或称该数据元素惟一地被主键所标识,例如学生表(学生id,姓名,成绩,合格状态),其中合格状态这一列不依赖于学生信息,而依赖于成绩,所以不符合第二范式
- 3NF:要求一个数据库表中不包含已在其它表中已包含的非主关键字信息,例如学生表(学生id,姓名,班级id,班级位置)班级表(班级id,班级名,班级位置),学生表里已经有了班级的id,可以推断出班级位置,无需在学生表里存入班级位置信息
BCNF:所有非主属性对每一个候选键都是完全函数依赖;所有的主属性对每一个不包含它的候选键,也是完全函数依赖;没有任何属性完全函数依赖于非候选键的任何一组属性
注意事项:
- 第二范式与第三范式的本质区别:在于有没有分出两张表。
第二范式是说一张表中包含了多种不同实体的属性,那么必须要分成多张表,第三范式是要求已经分好了多张表的话,一张表中只能有另一张标的ID,而不能有其他任何信息,(其他任何信息,一律用主键在另一张表中查询)。 - 必须先满足第一范式才能满足第二范式,必须同时满足第一第二范式才能满足第三范式。
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
五大约束
数据库中的五大约束包括:
- 主键约束(Primay Key Coustraint)唯一性,非空性;
- 唯一约束 (Unique Counstraint)唯一性,可以空,但只能有一个
- 默认约束 (Default Counstraint)该数据的默认值;
- 外键约束 (Foreign Key Counstraint)需要建立两表间的关系;
- 非空约束(Not Null Counstraint):设置非空约束,该字段不能为空。
select for update加锁
总结一下select…for update加锁的情况:
- 如果查询条件用了索引/主键,那么
select ..... for update就会进行行锁。 - 如果是普通字段(没有索引/主键),那么
select ..... for update就会进行锁表
主键字段:加行锁。
唯一索引字段:加行锁。
普通索引字段:加间隙锁。
主键范围:加多个行锁。
唯一索引范围,加多个行锁。
普通字段:加间隙锁,看着像表锁。。
查询空数据:加间隙锁。
如果事务1加了行锁,一直没有释放锁,事务2操作相同行的数据时,会一直等待直到超时。
如果事务1加了表锁,一直没有释放锁,事务2不管操作的是哪一行数据,都会一直等待直到超时。
此外,有些小伙伴,可能会好奇,直接执行update语句,也会加行锁,为什么还需要使用for update关键字加行锁呢?
答:for update关键字是加在select语句中的,它从查到那行数据开始,直到事务提交,整个过程中都会加锁。
而直接执行update语句,是在更新数据的时候加锁,二者有本质的区别。
MySQL中的distinct和group by哪个效率更高?
在语义相同,有索引的情况下:group by和distinct都能使用索引,效率相同。
在语义相同,无索引的情况下:distinct效率高于group by。原因是distinct和group by都会进行分组操作,但group by可能会进行排序,触发filesort,导致sql执行效率低下。
相关文章
怎么保证幂等性
幂等性的几种方案
唯一索引,防止新增脏数据
前端限制:页面的提交按钮只能被点击提交一次
后端解决方案:- 集群环境:采用token加redis(redis单线程的,处理需要排队)
- 单JVM环境:采用token加redis或token加jvm内存
处理流程:请求前先生成token,重复代表处理过.数据提交前向授权系统申请token,系统根据相关信息生成token并判断是否可以返回(根据代码逻辑将生成的token与已生成且保存的token做对比,token一致的话代表已经生成了一次,本次不允许返回),将生成的token放到redis或jvm内存,并设置token的有效时间,返回给客户端
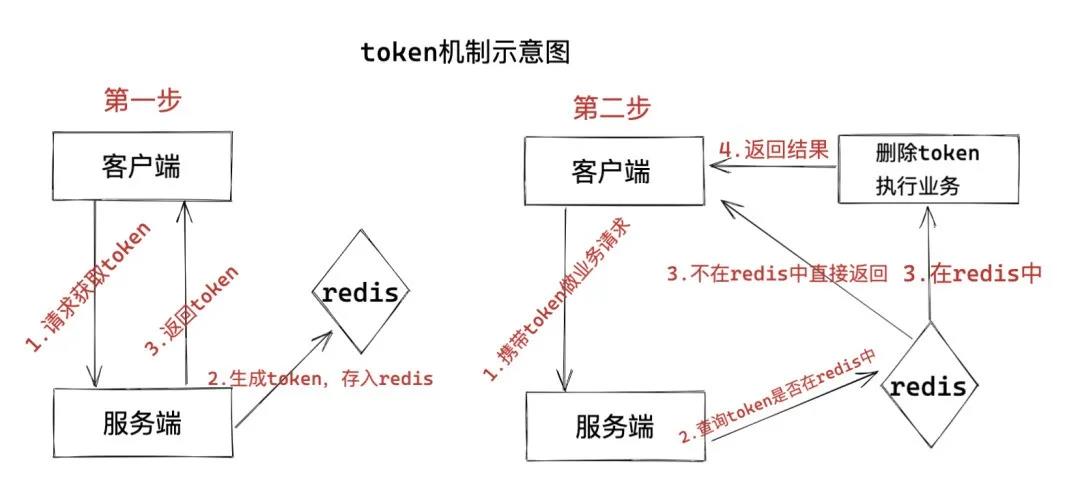
客户端携带token请求服务端,服务端查询redis,如果有的话处理请求并删除token,没有的话代表非法请求不做处理
现在很多系统处理请求已经不做是否登陆的校验,而是根据用户名密码申请token,将token保存到cookie或者Local Storage或者form隐藏域,请求时携带token,服务端校验处理请求
Token多平台身份认证架构设计思路
Token登录认证详解
- 悲观锁获取数据的时候加锁获取
select * from table_xxx where id='xxx' for update;注意:id字段一定是主键或者唯一索引
悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用
- 乐观锁:乐观锁只是在更新数据那一刻锁表,其他时间不锁表,所以相对于悲观锁,效率更高。乐观锁的实现方式多种多样可以通过version或者其他状态条件:
-- 通过版本号实现
update table_xxx set name=#name#,version=version+1 where version=#version#
-- 通过条件限制
update tablexxx set avaiamount=avaiamount-#subAmount# where avaiamount-#subAmount# >= 0分布式锁
状态机幂等
在设计单据相关的业务,或者是任务相关的业务,肯定会涉及到状态机(状态变更图),就是业务单据上面有个状态,状态在不同的情况下会发生变更,一般情况下存在有限状态机,如果状态机已经处于下一个状态,这时候来了一个上一个状态的变更,理论上是不能够变更的,这样的话,保证了有限状态机的幂等。注意:订单等单据类业务,存在很长的状态流转,一定要深刻理解状态机,对业务系统设计能力提高有很大帮助利用唯一请求编号去重,借用Redis做这个去重——只要这个唯一请求编号在redis存在,证明处理过,那么就认为是重复的
幂等性相关文章
微服务系统如何设计一个安全的API
- 身份认证问题
一般情况下服务端均会向客户端颁发appId、partnerId等类似于标识用户身份的唯一ID,此ID关联用户密钥,一旦服务端异常或者受到工具,可以追溯来源,调整ID状态或者来强制下线用户 - 信息泄露问题
信息泄露主要是要控制报文在网络传输中不要明文传输,根据对称和非对称加密算法的特点,目前主流的做法是使用混合加密,主要流程是,服务端创建RSA密钥对,将公钥传输给客户端,同时客户端创建AES密钥,使用AES密钥加密明文得到密文,接着使用公钥加密AES密钥,最后将加密后的AES密钥和密文传输到服务端。服务端使用自己的私钥解密加密后的AES密钥得到AES密钥,接着使用AES密钥解密密文得到明文 - 请求被篡改问题
防止请求被篡改主要是要做好加签和验签 - 重放攻击问题
黑客监听到请求后,重复请求攻击服务端,服务端如何识别是非法请求
在请求参数中增加timestamp、randomString参数【此参数是从服务端实时请求的】,服务端在接收到请求后timestamp时间戳和服务端相差1分中之内的才放行,接着判断randomString是否已经存在,如果存在则不响应
延时队列
| 生成订单30分钟未支付,则自动取消,该怎么实现? | 一口气说出6种实现延时消息的方案 | 面试官:怎么不用定时任务实现关闭订单? |
|---|---|---|
| 再有人问你如何实现订单到期关闭,就把这篇文章发给他 | 订单超时怎么处理?阿里用这种方案 | 怎么实现订单30分钟未支付自动取消?我有5种实现方案! |
反射
何为反射
如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
反射的应用场景
像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像Spring/SpringBoot、MyBatis等等框架中都大量使用了反射机制。这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。比如下面是通过JDK实现动态代理的示例代码,其中就使用了反射类Method来调用指定的方法。
public class DebugInvocationHandler implements InvocationHandler {
/**
* 代理类中的真实对象
*/
private final Object target;
public DebugInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
System.out.println("before method " + method.getName());
Object result = method.invoke(target, args);
System.out.println("after method " + method.getName());
return result;
}
}另外,像Java中的一大利器注解的实现也用到了反射。为什么你使用Spring的时候,一个@Component注解就声明了一个类为Spring Bean呢?为什么你通过一个@Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
反射机制的优缺点
优点:可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
缺点:让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。
反射相关文章
| Java反射机制你还不会?那怎么看Spring源码? | Java反射是什么?看这篇绝对会了! | 学会这篇反射,我就可以去吹牛逼了。 |
|---|---|---|
| 深入理解Java:类加载机制及反射 |
gist
Java相关
fastjson转换
// json = {"a":1,"b":2,"c":["d":3,"e":4]}
// json转JSONObject
JSONObject a = json.getJSONObject("a");
// json转JSONArray
JSONArray b = json.getJSONArray("c");
// json转对象
Map<String,Object> map = JSONObject.parseObject(json.get("c"),new TypeReference<Map<String,Object>>(){});
// 将Java对象序列化为JSON字符串,支持各种各种Java基本类型和JavaBean,避免value为null时过滤掉字段
JSONObject.toJSONString(data,SerializerFeature.WriteMapNullValue);
JSON.parse() JSON.parseObject()JSON.parseArray() json.get() ...获取路径
// http://localhost:8080/demo/course/index.jsp
// 返回:/demo
request.getContextPath()
// 返回当前页面所在目录下全名称:/course/index.jsp
request.getServletPath()
// 返回浏览器地址栏地址 http://localhost:8080/demo/course/index.jsp
request.getRequestURL()
// 返回包含工程名的当前页面全路径:/demo/course/index.jsp
request.getRequestURI()
// 返回 http://localhost:8080
request.getScheme()+"://"+request.getServerName()+":"+ request.getServerPort()
// 返回E:\apache-tomcat-7.0.82\webapps\jnhouse\
request.getSession().getServletContext().getRealPath(File.separator)
// 获取项目存放class文件的全路径 F:\zhongzhu\WebRoot\WEB-INF\classes
Thread.currentThread().getContextClassLoader().getResource("/").getPath()
//从classpath路径下获取资源并返回一个InputStream供读取文件
(this)类名.class.getClassLoader().getResourceAsStream("name")
// 会在当前类所在的包结构下查找相应的资源
类名.class.getResourceAsStream("name")
// 请求转发
return “forward:forward2.html”;
// 重定向
return “redirect:redirect2.html”;
request.getRequestDispatcher("url").forward(request, response)
response.sendRedirect("leader.htm");
list操作
// 交集 listA内容变为listA和listB都存在的对象 listB不变
listA.retainAll(listB)
// 差集 listA中存在listB的内容去重 listB不变
listA.removeAll(listB)
// 并集,为了去重,listA先取差集,然后追加全部的listB listB不变
listA.removeAll(listB) listA.addAll(listB)
// 将一个list平均切割2块
int sublistSize = (list.size() + 1) / 2;
List<Integer> sublist1 = list.subList(0, sublistSize);
List<Integer> sublist2 = list.subList(sublistSize, originalList.size());
// 将切分后的两个子列表分别添加到新的ArrayList中
resultList1.addAll(sublist1);
resultList2.addAll(sublist2);深拷贝
- 通过json化
import com.fasterxml.jackson.databind.ObjectMapper;
private <T> T deepCopy(T source) throws JsonProcessingException{
ObjectMapper objectMapper = new ObjectMapper();
String json = objectMapper.writeValueAsString(source);
T deepCopyTarget = objectMapper.readValue(json, new TypeReference<T>() {});
return deepCopyTarget;
}
// --延申--
//泛型方法,在方法名前指定类型参数(用尖括号<>括起来)
public <T> void methodName(T input) {
// 方法体
}
//不加'<>'的话T会被当做一个package里面的java类- 通过序列化
import java.io.*;
public class DeepCopyViaSerialization implements Serializable {
// 成员变量
public static <T extends Serializable> T deepCopy(T object) {
try {
// 序列化到字节数组
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bos);
out.writeObject(object);
// 反序列化到新对象
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream in = new ObjectInputStream(bis);
@SuppressWarnings("unchecked")
T copiedObj = (T) in.readObject();
return copiedObj;
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}- 使用三方库
一些第三方库如Apache Commons Lang的SerializationUtils也提供了序列化和反序列化的深拷贝方法,使用这些库可以简化深拷贝的实现。import org.apache.commons.lang3.SerializationUtils; public class DeepCopyWithApacheCommons { // 假设有一个类 public static <T extends Serializable> T deepCopy(T object) { return SerializationUtils.clone(object); } }
代码分页
Integer page = map.get("page");
Integer limit = map.get("rows");
Integer start = (page-1)*limit;
//List<Map<String,Object>> subList = list.subList(start,start+limit>list.size()?list.size():start+limit)
List<Map<String,Object>> subList = list.subList(start,Math.min(start+limit,list.size))
// stream
List<String> pageData = list.stream()
.skip((pageNum - 1) * pageSize) // 跳过前面的数据
.limit(pageSize) // 限制每页大小
.collect(Collectors.toList()); // 收集结果正则表达式
匹配数字,包括小数
var patten = /^[+-]?(0|([1-9]\d*))(\.\d+)?$/[+-] 中括号表示其内的内容都是符合要求的匹配,所以这个表示“+”或”-“
Matcher 类中group(0) 表示正则表达式中符合条件的字符串。
Matcher 类中group(1) 表示正则表达式中符合条件的字符串中的第一个()中的字符串。
Matcher 类中group(2) 表示正则表达式中符合条件的字符串中的第二个()中的字符串。
Matcher 类中group(3) 表示正则表达式中符合条件的字符串中的第三个()中的字符串。
group是针对()来说的,group(0)就是指的整个串,group(1)指的是第一个括号里的东西,group(2)指的第二个括号里的东西。
String line = "123ra9040 123123aj234 adf12322ad 222jsk22";
String pattern = "(\\d+)([a-z]+)(\\d+)";
// 创建Pattern对象
Pattern r = Pattern.compile(pattern);
// 现在创建matcher对象
Matcher m = r.matcher(line);
// m.find是否找到正则表达式中符合条件的字符串
while (m.find()) {
// 拿到上面匹配到的数据
System.out.println("Found value: " + m.group(0) );
System.out.println("Found value: " + m.group(1) );
System.out.println("Found value: " + m.group(2) );
System.out.println("Found value: " + m.group(3) );
}group(0)对应着((//d+)([a-z]+)(//d+))所匹配的数据123ra9040或者123123aj234或者222jsk22
group(2)输出的数据是group(0)中所匹配的数据,第二个括号的表达式,也就是([a-z]+)匹配到是数据ra或者aj或者jsk
group(3)输出的数据是group(0)中所匹配的数据,第三个括号的表达式,也就是(//d+)匹配到是数据9040或者234或者22
JS使用正则表达式
// 可以和java正则表达式共用,如果不使用new RegExp(),则和java正则表达式书写方式有差异
var patten = new RegExp("...")
patten.text(要匹配的内容)| 对正则表达式,这么多年你还在害怕吗 | 正则表达式手册 | 常用正则表达式最强整理(速查手册) |
|---|---|---|
| 给懒人开发者的一份正则表达式指南 |
冒泡排序
int[] arr = {2,5,4,1};
for(int i=0;i<arr.length-1;i++){
for(int j=0;j<arr.length-1-i;j++){
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
} JDK8 base64转换
String str = "str";
String encoded = Base64.getEncoder().encodeToString(str.getBytes( StandardCharsets.UTF_8));
String decoded = new String(Base64.getDecoder().decode(encoded), StandardCharsets.UTF_8);poi excel
public void creatExcel(File file,String code,String ts){
String[] header={"有功功率","时间","pss输出信号","时间"};
Workbook wb = new XSSFWorkbook();
Sheet sheet = wb.createSheet("sheet1");
Row rowFirst = sheet.createRow(0);
for(int i = 0;i<header.length;i++){
sheet.setColumnWidth(i, 5000);
}
for(int i = 0;i<header.length;i++){
Cell cell = rowFirst.createCell(i);
cell.setCellValue(header[i]);
}
for(int i =0;i<maxSize;i++){
Row row = sheet.createRow(i+1);
row.createCell(0).setCellValue("");
row.createCell(1).setCellValue("");
row.createCell(2).setCellValue("");
row.createCell(3).setCellValue("");
}
try{// 指定本地文件流
OutputStream os = new FileOutputStream(file);
// excel写入
wb.write(os);
os.close();
}catch(Exception e){
e.printStackTrace();
}
}
public void excel(HttpServletRequest request,HttpServletResponse response){
String[] handers = {"id","书名","作者","价格"};
List<Book> list = masterMapper.querySome(null,1,5);
try{
String filedisplay = "test.xlsx";
filedisplay = URLEncoder.encode(filedisplay, "UTF-8");
//由浏览器指定下载路径
//response.reset();
//response.setContentType("application/x-download");
//response.setContentType("application/vnd.ms-excel;charset=utf-8");
response.addHeader("Content-Disposition", "attachment;filename="+ filedisplay);
request.setCharacterEncoding("UTF-8");
response.setContentType("APPLICATION/OCTET-STREAM");
response.setHeader("Content-Dispostion","attachment;filename=".concat(filedisplay));
HSSFWorkbook wb = new HSSFWorkbook();//创建工作簿
HSSFSheet sheet = wb.createSheet("操作");//第一个sheet
HSSFRow rowFirst = sheet.createRow(0);//第一个sheet第一行为标题
rowFirst.setHeight((short) 500);
HSSFCellStyle cellStyle = wb.createCellStyle();// 创建单元格样式对象
cellStyle.setAlignment(HorizontalAlignment.CENTER); // 居中
cellStyle.setVerticalAlignment(VerticalAlignment.CENTER);
for (int i = 0; i < handers.length; i++) {
sheet.setColumnWidth(i, 4000);// 设置列宽
}
//写标题了
for (int i = 0; i < handers.length; i++) {
//获取第一行的每一个单元格
HSSFCell cell = rowFirst.createCell(i);
//往单元格里面写入值
cell.setCellValue(handers[i]);
cell.setCellStyle(cellStyle);
}
for (int i = 0; i < list.size(); i++) {
Book u = list.get(i);
//创建数据行
HSSFRow row = sheet.createRow(i + 1);
row.setHeight((short) 400); // 设置每行的高度
//设置对应单元格的值
row.createCell(0).setCellValue(u.getId());
row.getCell(0).setCellStyle(cellStyle);
row.createCell(1).setCellValue(u.getBookname());
row.getCell(1).setCellStyle(cellStyle);
row.createCell(2).setCellValue(u.getBookauthor());
row.getCell(2).setCellStyle(cellStyle);
row.createCell(3).setCellValue(u.getBookprice());
row.getCell(3).setCellStyle(cellStyle);
}
OutputStream os = response.getOutputStream();
wb.write(os);
os.close();
wb.close();
}catch(Exception e){
e.printStackTrace();
}
}ServletRequest常用方法
Object getAttribute(String name)
// 以Object形式返回指定属性的值,如果不存在给定名称的属性,则返回null。
Enumeration getAttributeNames()
// 返回包含此请求可用属性的名称的Enumeration。如果该请求没有可用的属性,则此方法返回一个空的Enumeration。
String getCharacterEncoding()
// 返回此请求正文中使用的字符编码的名称。如果该请求未指定字符编码,则此方法返回null
void setCharacterEncoding(String env)
// 重写此请求正文中使用的字符编码的名称。必须在使用getReader() 读取请求参数或读取输入之前调用此方法。否则,此方法没有任何效果。
int getContentLength()
// 返回请求正文的长度(以字节为单位),并使输入流可以使用它,如果长度未知,则返回-1。对于HTTP servlet,返回的值与CGI变量 CONTENT_LENGTH的值相同。
String getContentType()
// 返回请求正文的MIME类型,如果该类型未知,则返回null。对于HTTP servlet,返回的值与CGI变量CONTENT_TYPE的值相同。
ServletInputStream getInputStream()
// 使用ServletInputStream以二进制数据形式获取请求正文。可调用此方法或getReader读取正文,而不是两种方法都调用。
String getParameter(String name)
// 以String形式返回请求参数的值,如果该参数不存在,则返回null。请求参数是与请求一起发送的额外信息。对于HTTP servlet,参数包含在查询字符串或发送的表单数据中。
Enumeration getParameterNames()
// 返回包含此请求中所包含参数的名称的String对象的Enumeration。如果该请求没有参数,则此方法返回一个空的Enumeration。
String[] getParameterValues(String name)
// 返回包含给定请求参数拥有的所有值的String对象数组,如果该参数不存在,则返回null。
Map<K, V> getParameterMap()
// 返回此请求的参数的 java.util.Map。请求参数是与请求一起发送的额外信息。对于HTTP servlet,参数包含在查询字符串或发送的表单数据中。
String getProtocol()
// 以protocol/majorVersion.minorVersion的形式(例如HTTP/1.1)返回请求使用的协议的名称和版本。对于HTTP servlet,返回的值与CGI变量SERVER_PROTOCOL的值相同。
String getScheme()
// 返回用于发出此请求的方案的名称,例如http、https或ftp。不同方案具有不同的构造URL的规则,这一点已在RFC 1738中注明。
String getServerName()
// 返回请求被发送到的服务器的主机名。它是Host头值“:”(如果有)之前的那部分的值,或者解析的服务器名称或服务器IP地址。
int getServerPort() // 返回请求被发送到的端口号。它是Host头值“:”(如果有)之后的那部分的值,或者接受客户端连接的服务器端口。
BufferedReader getReader()
// 使用BufferedReader以字符数据形式获取请求正文。读取器根据正文上使用的字符编码转换字符数据。可调用此方法或getInputStream读取正文,而不是两种方法都调用。
String getRemoteAddr()
// 返回发送请求的客户端或最后一个代理的Internet Protocol (IP)地址。对于HTTP servlet,返回的值与CGI变量REMOTE_ADDR的值相同。
String getRemoteHost()
// 返回发送请求的客户端或最后一个代理的完全限定名称。如果引擎无法或没有选择解析主机名(为了提高性能),则此方法返回以点分隔的字符串形式的IP地址。对于HTTP servlet,返回的值与CGI变量REMOTE_HOST的值相同。
void setAttribute(String name, Object o)
// 存储此请求中的属性。在请求之间重置属性。此方法常常与RequestDispatcher一起使用。
void removeAttribute(String name)
// 从此请求中移除属性。此方法不是普遍需要的,因为属性只在处理请求期间保留。
Locale getLocale()
// 基于Accept-Language头,返回客户端将用来接受内容的首选Locale。如果客户端请求没有提供Accept-Language头,则此方法返回服务器的默认语言环境。
Enumeration getLocales()
// 返回Locale对象的Enumeration,这些对象以首选语言环境开头,按递减顺序排列,指示基于Accept-Language头客户端可接受的语言环境。如果客户端请求没有提供Accept-Language头,则此方法返回包含一个Locale的Enumeration,即服务器的默认语言环境。
boolean isSecure()
// 返回一个boolean值,指示此请求是否是使用安全通道(比如HTTPS)发出的。
RequestDispatcher getRequestDispatcher(String path)
// 返回一个RequestDispatcher对象,它充当位于给定路径上的资源的包装器。可以使用RequestDispatcher对象将请求转发给资源,或者在响应中包含资源。资源可以是动态的,也可以是静态的。
String getRealPath(String path)
// 从Java Servlet API的版本2.1起,请改用ServletContext#getRealPath
int getRemotePort()
// 返回发送请求的客户端或最后一个代理的Internet Protocol (IP)源端口。
String getLocalName()
// 返回接收请求的Internet Protocol (IP)接口的主机名。
String getLocalAddr()
// 返回接收请求的接口的Internet Protocol (IP)地址。
int getLocalPort()
// 返回接收请求的接口的Internet Protocol (IP)端口号。HttpServletRequest
Cookies getCookies()
// 返回包含客户端随此请求一起发送的所有Cookie对象的数组。
long getDateHeader(String name)
// 以表示Date对象的long值的形式返回指定请求头的值。
String getHeader(String name)
// 以String的形式返回指定请求头的值。
Enumeration getHeaders(String name)
// 以String对象的Enumeration的形式返回指定请求头的所有值。
Enumeration getHeaderNames()
// 返回此请求包含的所有头名称的枚举。如果该请求没有头,则此方法返回一个空枚举。
int getIntHeader(String name)
// 以int的形式返回指定请求头的值。
String getMethod()
// 返回用于发出此请求的HTTP方法的名称,例如GET、POST或PUT。返回的值与CGI变量REQUEST_METHOD的值相同。
String getPathInfo()
// 返回与客户端发出此请求时发送的URL相关联的额外路径信息。额外路径信息位于servlet路径之后但在查询字符串之前,并且将以“/”字符开头。
String getPathTranslated()
// 返回在servlet名称之后但在查询字符串之前的额外路径信息,并将它转换为实际路径。返回的值与CGI变量PATH_TRANSLATED的值相同。
String getContextPath()
// 返回请求URI指示请求上下文的那一部分。请求URI中首先出现的总是上下文路径。路径以“/”字符开头但不以“/”字符结束。对于默认(根)上下文中的servlet,此方法返回“”。容器不会解码此字符串。
String getQueryString()
// 返回包含在请求URL中路径后面的查询字符串。如果URL没有查询字符串,则此方法返回null。返回的值与CGI变量QUERY_STRING的值相同。
String getRequestedSessionId()
// 返回客户端指定的会话ID。此值可能不同于此请求的当前有效会话的ID。如果客户端没有指定会话ID,则此方法返回null。
String getRequestURL()
// 重新构造客户端用于发出请求的URL。返回的URL包含一个协议、服务器名称、端口号、服务器路径,但是不包含查询字符串参数。
String getServletPath()
// 返回此请求调用servlet的URL部分。此路径以“/”字符开头,包括servlet名称或到servlet的路径,但不包括任何额外路径信息或查询字符串。返回的值与CGI变量SCRIPT_NAME的值相同。
HttpSession getSession(boolean create)
// 返回与此请求关联的当前HttpSession,如果没有当前会话并且create为true,则返回一个新会话。
HttpSession getSession()
// 返回与此请求关联的当前会话,如果该请求没有会话,则创建一个会话。
boolean isRequestedSessionIdValid()
// 检查请求的会话ID是否仍然有效。
boolean isRequestedSessionIdFromCookie()
// 检查请求的会话ID是否是作为cookie进入的。
boolean isRequestedSessionIdFromURL()
// 检查请求的会话ID是否是作为请求URL的一部分进入的。前端相关
jsp获取session数据
<%=session.getAttribute("name")%>
or
${sessionScope.name}easyui combobox下拉框设置checkbox全选
function initCombobox(id,data){
var value = "";
//加载下拉框复选框
$('#'+id).combobox({
data:data, //后台获取下拉框数据的url
method:'post',
panelHeight:200,//设置为固定高度,combobox出现竖直滚动条
valueField:'id',
textField:'text',
multiple:true,
editable:false,
formatter: function (row) { //formatter方法就是实现了在每个下拉选项前面增加checkbox框的方法
var opts = $(this).combobox('options');
var checkbox_id = row.check_id;
if(checkbox_id){
return '<input type="checkbox" class="combobox-checkbox" id="' + checkbox_id +'">' + row[opts.textField]
}
return '<input type="checkbox" class="combobox-checkbox">' + row[opts.textField]
},
onLoadSuccess: function () {//下拉框数据加载成功调用
var opts = $(this).combobox('options');
var target = this;
var values = $(target).combobox('getValues');//获取选中的值的values
$.map(values, function (value) {
var el = opts.finder.getEl(target, value);
el.find('input.combobox-checkbox')._propAttr('checked', true);
})
},
onSelect: function (row) { //选中一个选项时调用
var opts = $(this).combobox('options');
//当点击所有时,则勾中所有的选项
if (row.text === "全选") {
var data = $("#"+id).combobox('getData');;
var show_type = $("#show_type").combobox('getValue');
for (var i = 0; i < data.length; i++) {
//获取选中的值的values
$("#"+id).val($(this).combobox('getValues'));
// 选择全部和按照机组展示全选时才选中发电类型 机组类型 供热状态 否则不选择这三个
if(show_type != '6' && show_type != ''){
var field = data[i][opts.valueField];
if(field == 'fdlx' || field == 'grqk' || field == 'unit_status'){
continue;
}
}
//设置选中值所对应的复选框为选中状态
var el = opts.finder.getEl(this, data[i][opts.valueField]);
el.find('input.combobox-checkbox')._propAttr('checked', true);
}
var list = [];
$.map(opts.data, function (opt) {
// 选择全部和按照机组展示全选时才选中发电类型 机组类型 供热状态 否则不选择这三个
if(show_type != '6' && show_type != ''){
if(opt.id != 'fdlx' && opt.id != 'grqk' && opt.id != 'unit_status'){
list.push(opt.id);
}
}else{
list.push(opt.id);
}
});
$("#"+id).combobox('setValues', list); // combobox全选
} else {
//获取选中的值的values
$("#"+id).val($(this).combobox('getValues'));
//设置选中值所对应的复选框为选中状态
var el = opts.finder.getEl(this, row[opts.valueField]);
el.find('input.combobox-checkbox')._propAttr('checked', true);
}
},
onUnselect: function (row) {//不选中一个选项时调用
var opts = $(this).combobox('options');
if (row.text === "全选") {
var a = $("#"+id).combobox('getData');
for (var i = 0; i < a.length; i++) {
$("#"+id).val($(this).combobox('getValues'));
var el = opts.finder.getEl(this, data[i][opts.valueField]);
el.find('input.combobox-checkbox')._propAttr('checked', false);
}
$("#"+id).combobox('clear');//清空选中项
} else {
//获取选中的值的values
$("#"+id).val($(this).combobox('getValues'));
var el = opts.finder.getEl(this, row[opts.valueField]);
el.find('input.combobox-checkbox')._propAttr('checked', false);
}
}
});
}其他
二叉树遍历
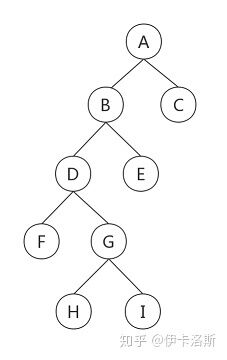
前序遍历A-B-D-F-G-H-I-E-C
中序遍历F-D-H-G-I-B-E-A-C
后序遍历F-H-I-G-D-E-B-C-A
前序(根左右),中序(左根右),后序(左右根)
py import
import math
print math.pi
# 等价于
from math import pi
print piexcel查看路径和文件名
在任一单元格输入=CELL("filename")即可windows杀掉进程
taskkill /pid pid
# /f 强制
# /t 终止进程和他启用的子进程
taskkill /? # 查看相关用法
tasklist # 查看所有进程cron表达式
3/12 第三分钟开始,每12分钟触发
12,15,17 第12分钟、15分钟、17分钟触发
3-19 看使用在哪个域 如果在minute域则表示在第3分钟到第19分钟每分钟触发一次 在second域则表示从第3秒到第19秒每秒触发一次
24 43 2 ? 1-12 3 * 每周三2点43分24秒触发一次
秒杀
步骤
写脚本肯定需要知道步骤是什么,然后才能用代码去复刻下来嘛。
1、下载浏览器驱动,这里我用的是chrome浏览器,先看一下自己的版本号,在设置可以看到。
然后在网站找好对应的版本去下载
2、接下来就是设置秒杀时间
3、打开浏览器输入淘宝网址
4、登录账号,进入购物车页面
5、点击选择按钮
6、秒杀时间到了,立刻下单!
操作开始
导入依赖:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>下面是完整的代码
public void taoBao() throws Exception {
// 浏览器驱动路径
System.setProperty("webdriver.chrome.driver","D:\\JDK\\chromedriver.exe");
// 设置秒杀时间
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSSSSSSSS");
Date date = sdf.parse("2022-04-14 14:07:00 000000000");
// 1、打开浏览器
ChromeDriver browser = new ChromeDriver();
Actions actions = new Actions(browser);
// 2、输入网址
browser.get("https://www.taobao.com");
Thread.sleep(3000);
// 3、点击登录
browser.findElement(By.linkText("亲,请登录")).click();
Thread.sleep(2000);
// 4、扫码登录
browser.findElement(By.className("icon-qrcode")).click();
Thread.sleep(4000);
// 5、进入购物车页面
browser.get("https://cart.taobao.com/cart.htm");
Thread.sleep(3000);
// 6、点击选择第一个按钮
browser.findElement(By.xpath("//*[@id=\"J_Order_s_2207407355826_1\"]/div[1]/div/div/label")).click();
Thread.sleep(2000);
while (true){
//当前时间
Date now = new Date();
System.out.println(now);
if(now.after(date)){
if(browser.findElement(By.linkText("结 算")).isEnabled()){
browser.findElement(By.linkText("结 算")).click();
System.out.println("结算成功");
break;
}
}
}
Thread.sleep(5000);
}这里说一下会遇到的问题:
- 这里使用的是扫码登录,需要用手机淘宝扫码进行登录
- Thread.sleep(4000);就是系统休息4秒钟,如果扫码登录时间大于4秒会报错,可以根据电脑网速来设置
- browser.findElement(By.xpath(“xxx”)).click();这个是选择购物车第一个商家的所有商品,里面xxx需要更改。当然其他参数怎么修改可以根据这个对应来修改。
进入购物车页面后按F12,然后点左上角那个箭头,然后选择店铺左边的按钮,这样下面代码块就对应到了指定的代码位置

右键这一行,然后选择copy→Copy XPath,这个XPath就是browser.findElement(By.xpath(“xxx”)).click();的xxx内容

如果以上操作都没有问题,那么你就可以启动程序啦!!成功后你会发现,脚本居然如此简单!!
| 面试官:你给我画一下秒杀系统的架构图 | 秒杀场景的九个细节,细思极恐! | 秒杀系统设计最全攻略 |
|---|---|---|
| 下次二面再回答不好“秒杀系统“设计原理,我就捶死自己… | 如何设计订单系统 | 千万级高并发秒杀系统设计套路 |
安卓ROOT大法
线刷
- 电脑可以使用fastboot、adb等命令
- 下载magisk
- 解锁BL
- 提取boot.img
- 使用magisk制作boot.img,将生成的文件拷贝到电脑,生成路径一般在download文件夹下
- 进入fastboot模式(一般在关机状态下长按音量减+电源键)
- 使用
fastboot flash boot magisk制作的img文件路径.img - 使用
fastboot reboot重启 - 完成
卡刷
- 安装第三方recovery如twrp,镜像文件为recovery.img
- 手机进入fastboot模式,使用
fastboot flash recovery recovery.img并重启手机 - 将magisk.apk重命名为magisk.zip
链接
注意事项
magisk如果收不到其他app授权申请弹窗的话授权magisk悬浮窗和自启动权限
PS相关操作
换证件照底色
打开图片-选择主体-选择并遮住-调整下细节-输出带有蒙版图层-新建图层(不是(ctrl+j)复制图层)- ctrl+del(填充背景色)或者alt+del(填充前景色)-调整图层位置-完成。其中蓝色背景的色号一般为:#0033A0(深蓝色),RGB色值为R:67, G:142, B:2191。白色背景的色号是:#FFFFFF(纯白色),RGB色值为R:255, G:255, B:2551。红色背景的色号可以为:#C8102E(标准红色),RGB色值为R:255, G:0, B:01.
更换大小眼
打开图片-ctrl+j复制图层-套索工具选中眼睛-移到小眼睛位置-右键水平翻转-调整-右上角对号应用
瘦脸
滤镜-液化
去水印
- 矩形选框工具选中水印选择“编辑”-“填充”(快捷键:Shift+F5),属性选“内容识别”点击“确定”,取消选区。
- 选择“污点修复画笔工具”
磁盘阵列
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种数据存储虚拟化技术,它将多个物理磁盘组合成一个逻辑单元,目的是为了提高数据的冗余性和性能。不同的RAID级别代表了不同的配置方法,每种配置都有其特定的优势和应用场景。
RAID 0
RAID 0,也称为条带卷,它将数据分散存储在两个或更多的硬盘上,但不提供冗余。这意味着如果任何一个硬盘失败,所有数据都会丢失。然而,由于数据是分散存储的,所以读写速度非常快,适合对性能要求高的应用,如视频编辑。但它的缺点是没有容错能力。
RAID 1
RAID 1提供了镜像功能,即数据会在两个或更多的硬盘上完全复制。这提供了很好的冗余性,因为即使一个硬盘失败,数据仍然可以从另一个硬盘上读取。RAID 1适合对数据安全性要求极高的场景,但缺点是只有一半的存储空间可用,且写入速度会受到影响。
RAID 5
RAID 5至少需要三个硬盘,它通过条带化与奇偶校验相结合的方式来存储数据。这种配置允许单个硬盘的失败而不会丢失数据,因为可以通过剩余硬盘上的数据和奇偶校验信息重建丢失的数据。RAID 5的优点是提供了平衡的性能和冗余性,但写入性能相对较低,且在硬盘故障时重建数据的速度较慢。
RAID 6
RAID 6类似于RAID 5,但它使用两个奇偶校验块而不是一个,这意味着它可以容忍两个硬盘同时失败。这提供了更高的数据安全性,但与RAID 5相比,它的写入性能更低,且成本更高。
RAID 10
RAID 10结合了RAID 1和RAID 0的特点,提供了镜像和条带化的优势。它将数据分散存储在多个硬盘上,并在另一组硬盘上创建数据的完整副本。这种配置提供了很好的性能和冗余性,但与RAID 1一样,它的存储效率只有50%。
在选择适合的RAID级别时,需要考虑数据的重要性、性能需求、存储容量和预算。例如,如果数据安全性是首要考虑的,那么RAID 1或RAID 6可能是更好的选择。如果性能是关键因素,RAID 0或RAID 10可能更合适。对于需要平衡性能和冗余性的场景,RAID 5是一个常见的选择。
总的来说,RAID 0适合性能要求高但不需要冗余的场景,RAID 1适合数据安全性要求高的场景,RAID 5和RAID 6适合需要平衡性能和冗余性的场景,而RAID 10提供了最佳的性能和冗余性,但代价是较高的成本和较低的存储效率。



